Analysing Amazon's Buckets
Wed 25th May 11
So, as I promised, here is some analysis of the data I got from running my Bucket Finder tool.
I decided to run it with a list of names as I figured that most people creating buckets will probably name them after themselves. Rather than run a huge list to start off I went with the list of common names from Packet Storm. This list contain 2268 names and didn't take too long to run through, here are is a breakdown of the results.
Buckets
| Type | Count |
|---|---|
| Don't Exist | 1206 |
| Private | 848 |
| Public | 131 |
As you can see, most of the names tried don't exist but 5% do and are public, I think this is a good hit rate. Packet Storm has other word lists which top 100,000 words, if the same return is true then we are looking at over 5000 buckets to investigate.
Files
Of the public buckets found this is the breakdown of the files found in them:
| Type | Count |
|---|---|
| Private | 6016 |
| Public | 9683 |
| Total | 15699 |
This shows that when buckets are made public around one third of users still put private files in them. This may imply that people using the system know what they are doing and are deliberately choosing what files to share and what to keep private or it may be that some of the applications being used to manage the buckets require them to be public but then create the files in the buckets as private.
Finally, here is a breakdown of the public file types I found based on file extension:
| Type | Extensions | Count |
|---|---|---|
| Images | jpg|png|gif|tiff|psd|bmp | 7086 |
| Web | html|css|js | 1377 |
| Videos and Music | mp3|mp4|flv|mov|avi|wmv|m4v|aa|mpg | 436 |
| Documents | pdf|doc|xls|ppt | 80 |
| Archives | rar|zip|gz | 57 |
| SQL | sql | 1 |
| Other | 646 | |
| Total | 9683 |
And a pretty pie chart to show it as well:
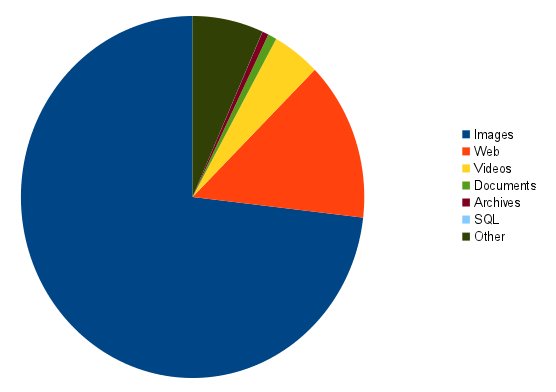
Most people are using S3 to store images, I grabbed random selections of these and found they were mostly personal photo collections, lots of photos of babies implying people wanting to share and finding Amazon a good way to throw them quickly onto the net.
Browsing some of the documents I found an MOD training requisition form, including SSN and loads of other personal data, a couple of sets of company accounts and some other company documents that really shouldn't have been online.
The videos didn't reveal much interesting, mostly training and motivational things from the ones I grabbed.
In the music category there were a few people sharing large mp3 collections with the world and I now have a couple of new bands whose music I'll be following.
All-in-all, a pretty mixed bag. There are definitely some gems in there that are worth pulling out but with the amount of data to trawl through it is either going to take a lot of human hours or some very good automation to try to spot them. If anyone has ideas on how to automate this let me know and I'll see what I can do about building things in.
